Сценарии использования#
Сценарий 1: Обработка грязных данных
Функция Удалить дублирующиеся строки полезна при очистке грязных данных и удалении дублей.
Например, если строка с данными по заказу попадает в таблицу дважды, удалив дублирующуюся строку, останется только одна запись по заказу.
Сценарий 2: Сохранение части данных
Для сбора данных о статусе оборудования при случайной выборке распределение строк может быть неравномерным, например, за минуту собирается 10–20 строк. В этом случае с помощью Удалить дублирующиеся строки можно оставить только одну строку на каждую минуту.
Сценарий 3: Удаление дублирующихся строк
Если требуется анализировать только уникальные пользовательские данные в широкой таблице, сначала удалите ненужные поля через Настройки поля, затем выполните Удалить дублирующиеся строки для очистки дубликатов по требуемым полям.
Описание функции#
Система проверяет, есть ли строки с одинаковыми значениями в выбранных для дедупликации полях. Если выбрать Выбрать все в списке Выбор поля дедупликации, система ищет повторения по всем полям.
При наличии дублей система сохраняет только первую строку.
Пример#
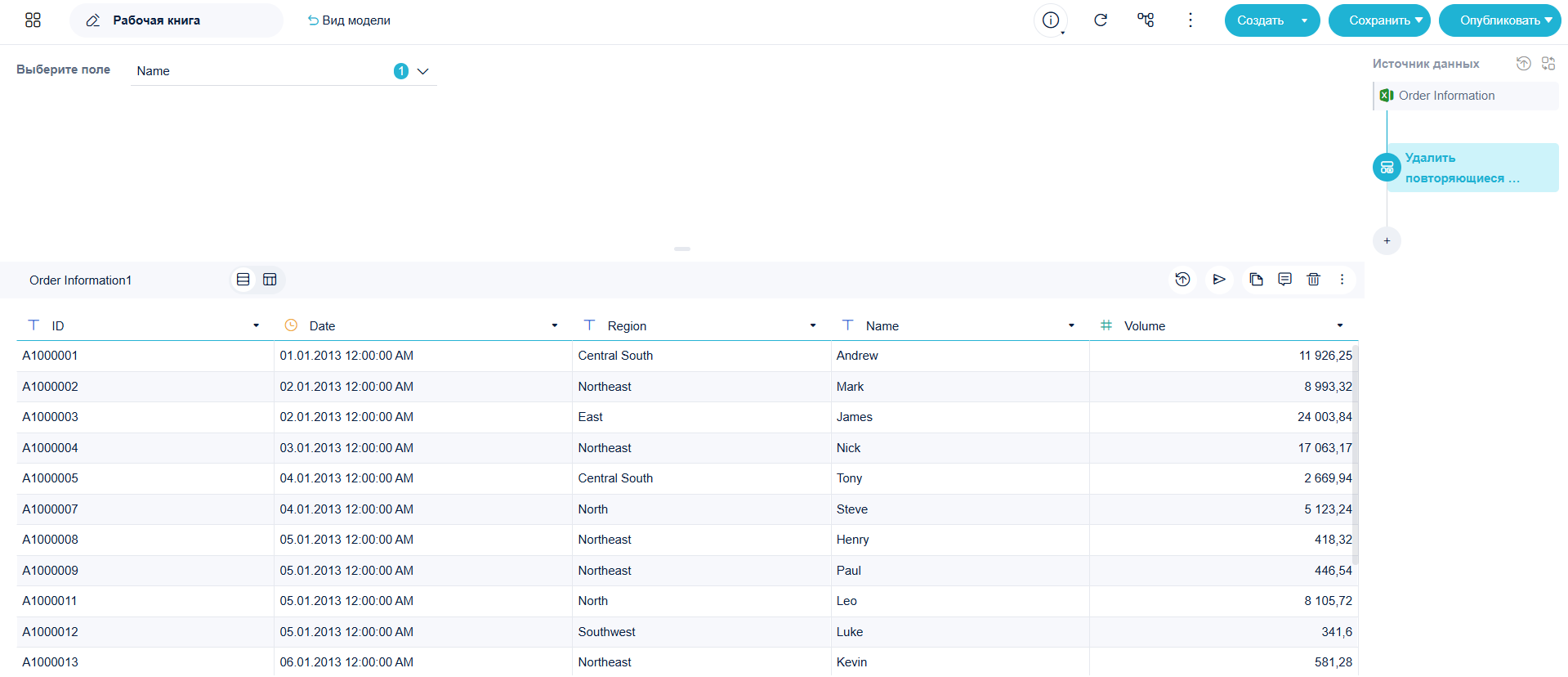
- Загрузите данные в рабочую книгу, как показано на рисунке.
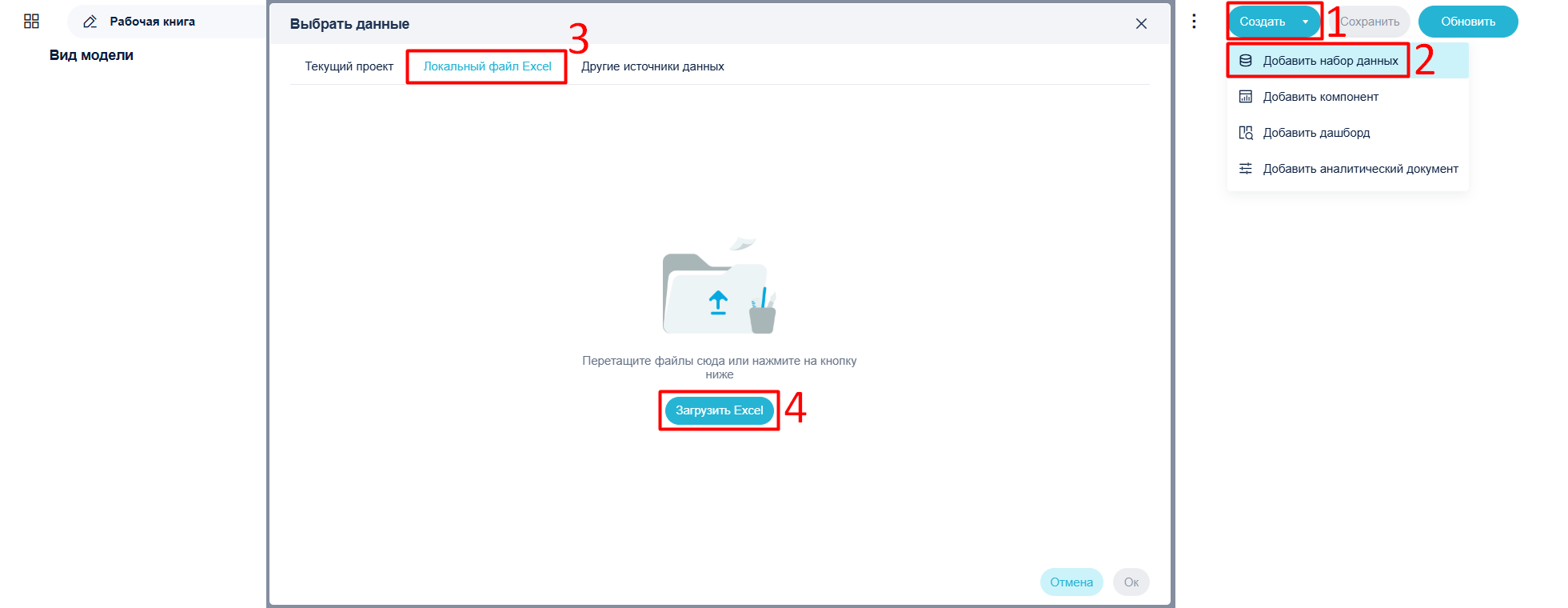
- Нажмите + -> Ещё и выберите Удалить повторяющиеся строки.
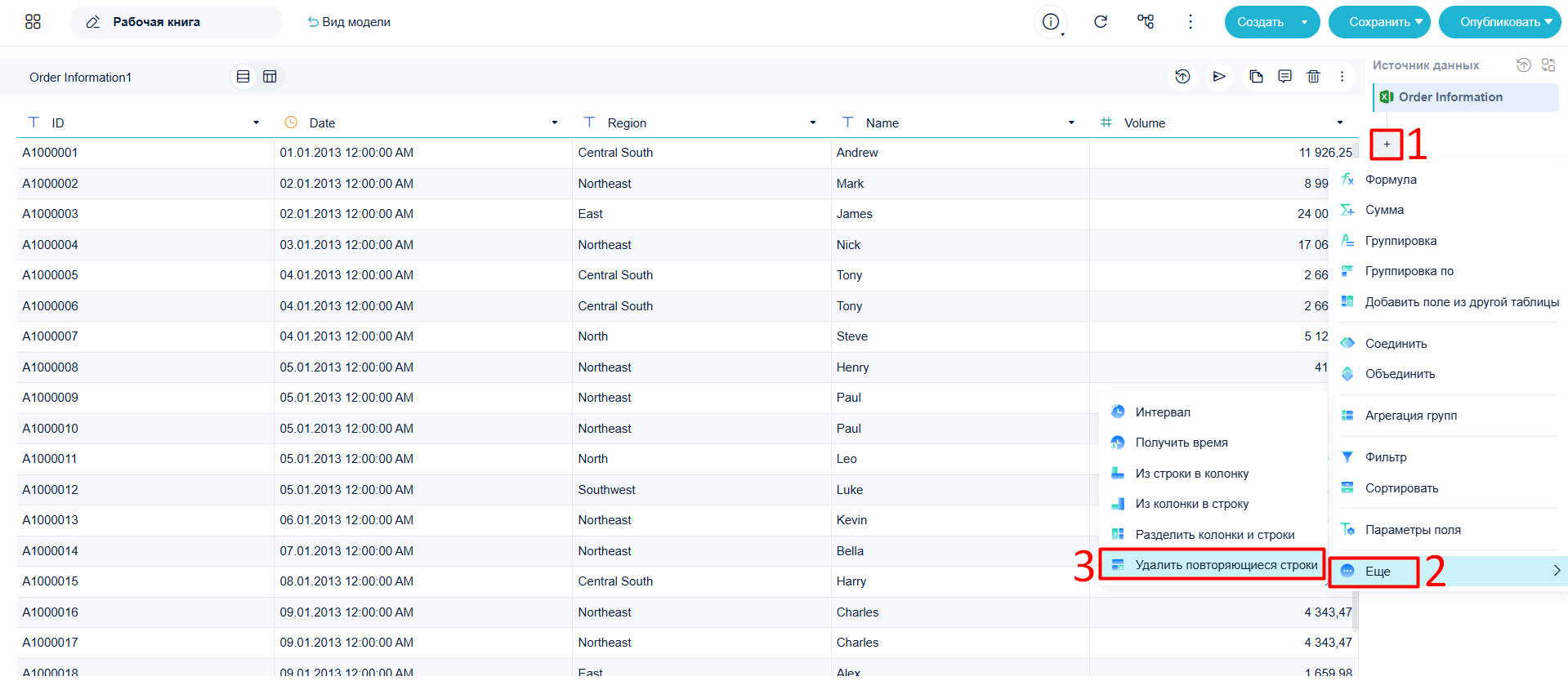
- Система определяет, являются ли строки дубликатами по выбранным полям. Если значения в полях Date, Name и Volume совпадают — это дубликат одного заказа.
Выберите поля Date, Name и Volume как критерии для поиска дублей.
Примечание:Система по умолчанию оставляет первую строку из найденных дубликатов. Например, если значения A1000005 и A1000006 совпадают, сохраняется только A1000005.
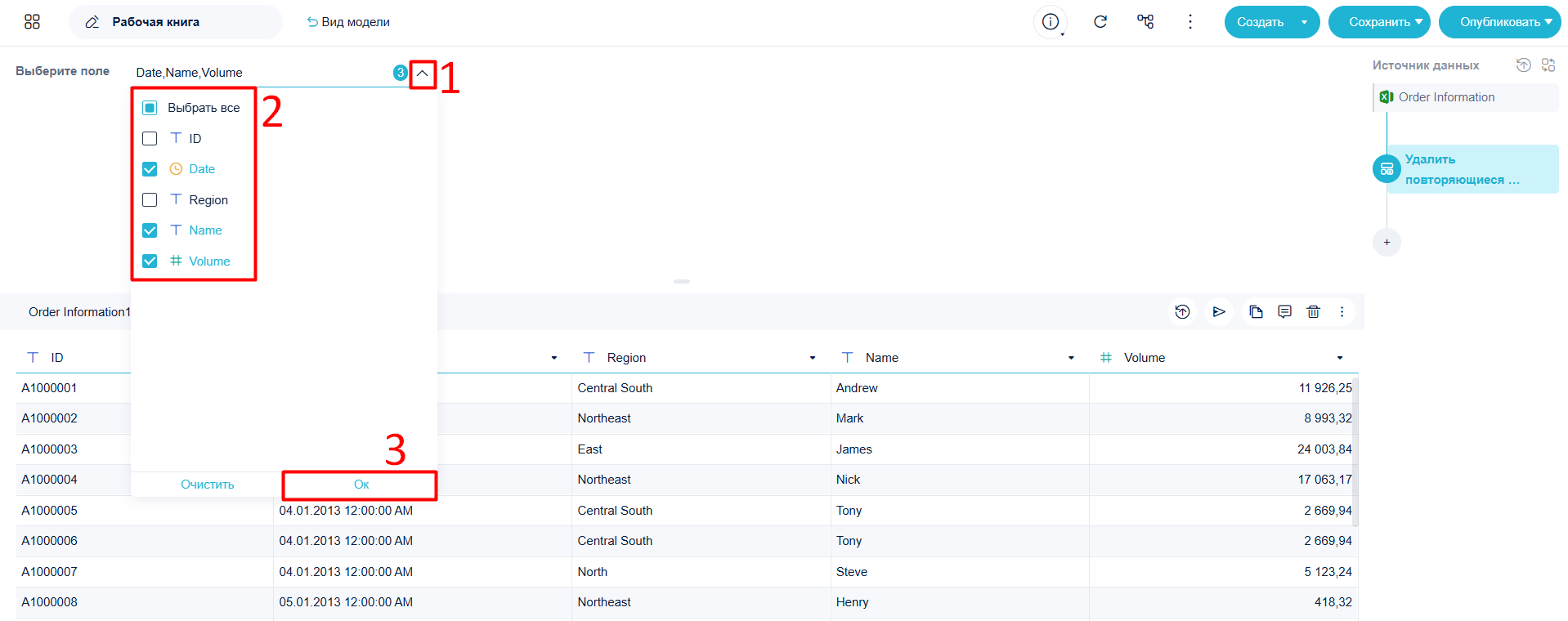
- Нажмите Сохранить для получения очищенных данных без дубликатов.
Ниже приведён результат, как могут отличаться итоговые данные в зависимости от выбранных для дедупликации полей:
- Region - для каждого региона сохранится только одна строка заказа
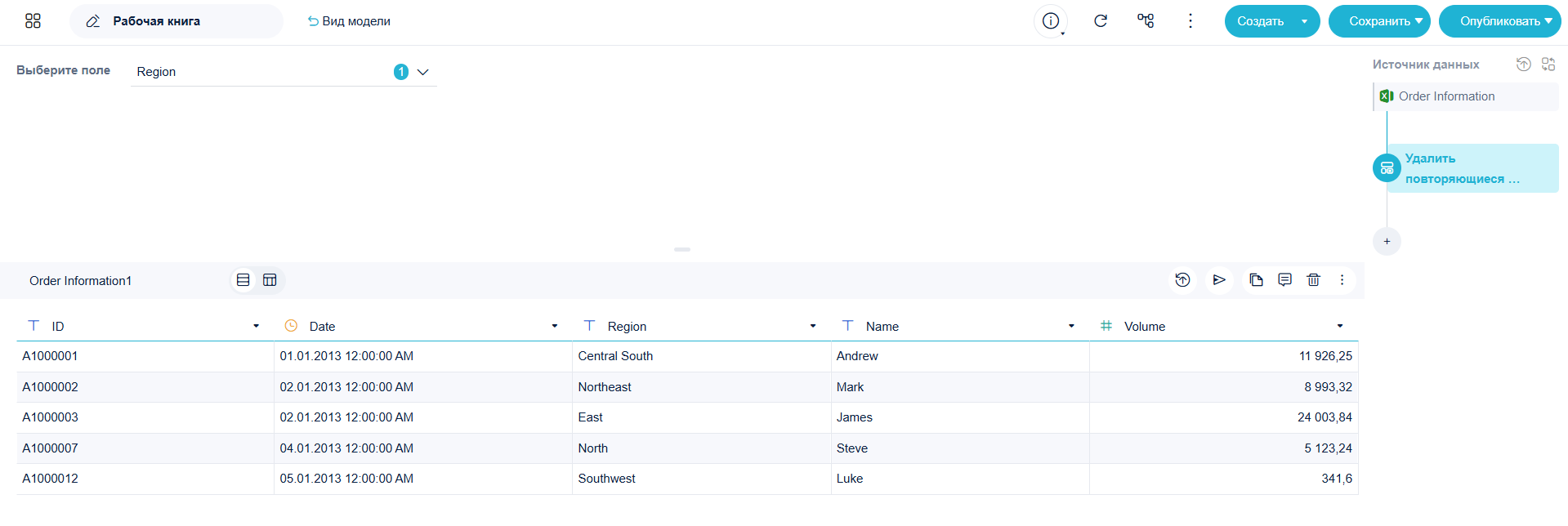
- Name - для каждого пользователя сохранится только одна строка заказа
Рекомендация по использованию#
По умолчанию система сохраняет первую из дублирующихся строк, которая стоит выше остальных. Это означает, что при выполнении Удалить дублирующиеся строки на разных шагах может сохраняться разная строка. Рекомендуется выполнять Удалить дублирующиеся строки на последнем шаге подготовки данных.