После ознакомления с этим разделом вы поймёте основной принцип объединения данных в модели рабочей книги. Этот принцип — ключевое отличие модели рабочей книги от объединения через джойн, и именно он обеспечивает большую эффективность.
Логика соединения (джойна)#
Объединение через джойн — это объединение на уровне строк, где таблицы связываются по общим значениям столбцов.
Порядок объединения данных через джойн таков:
- При объединении типа «один к одному» всё просто — соедините таблицы по полю Регион.
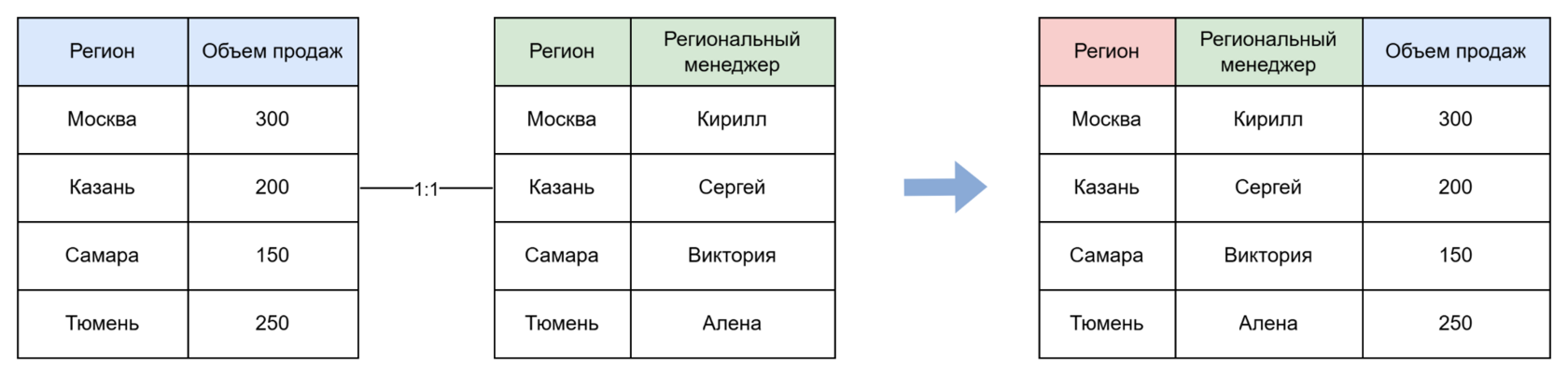
- В случае объединения «многие к одному»: если слева добавлено поле Офис, то, например, для Москвы и Самары в поле Регион появляется по две строки.
При объединении правой таблицы через Регион, данные по этим регионам тоже дублируются. В итоговой таблице поле Региональный менеджер повторится.
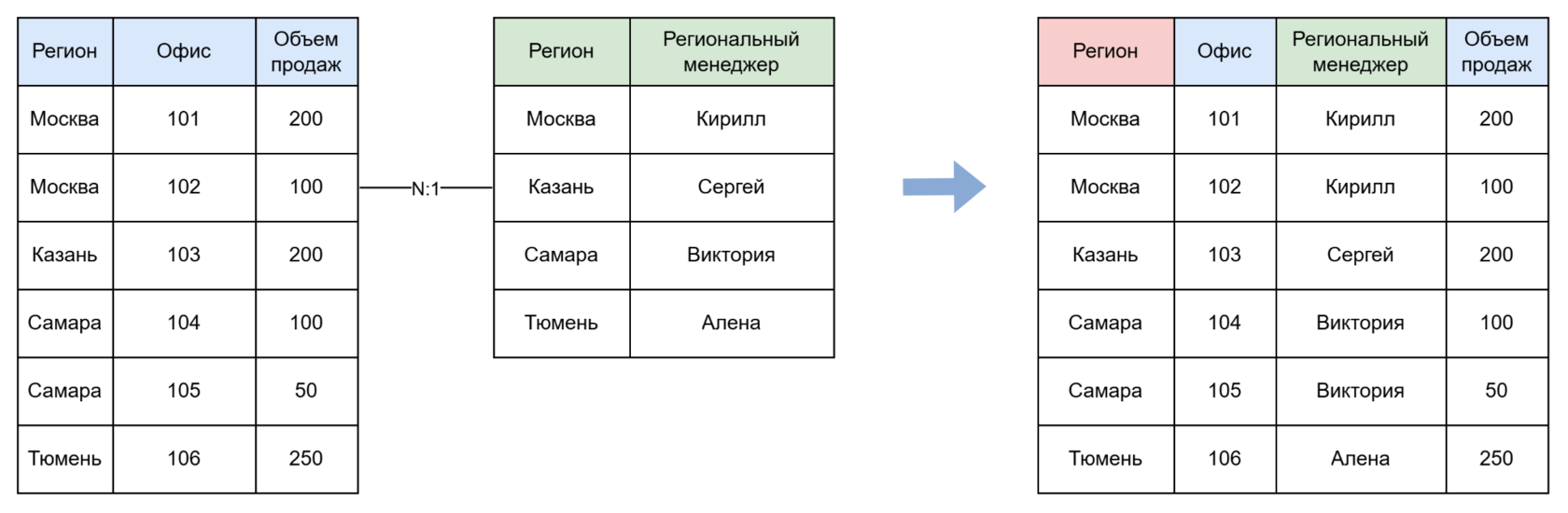
Дублирование данных в измерениях (например, Региональный менеджер) не повлияет на аналитику. Но если дублируются показатели (например, поле Целевые продажи), это уже влияет на итоговые расчёты — например, сумма по столбцу Целевые продажи окажется неверной.
Вывод: дублирование информации по показателям приводит к увеличению данных и ошибкам, дублирование по измерениям — нет.
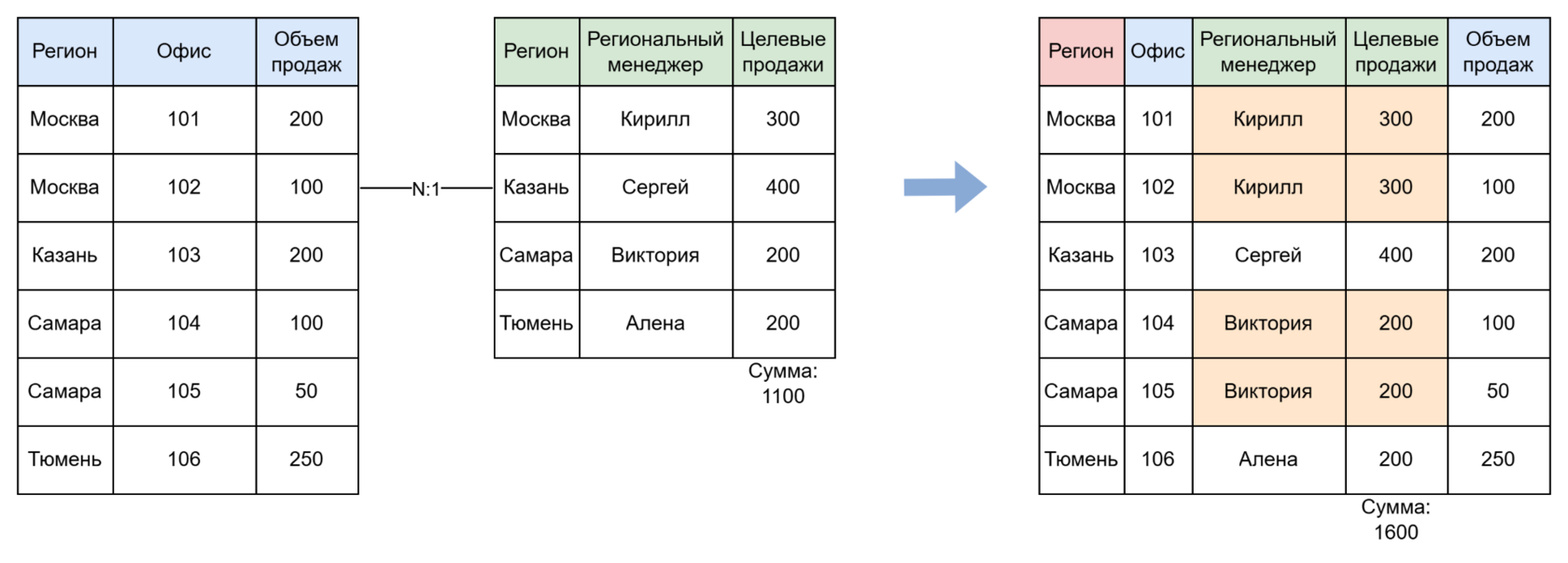
- Если в N-к-N объединении дублируются поля-показатели, возникает полный хаос.
Например, объёмы продаж и количество сотрудников тоже продублируются (например, по Москве будет уже 4 строки). Итоговые суммы будут некорректны.
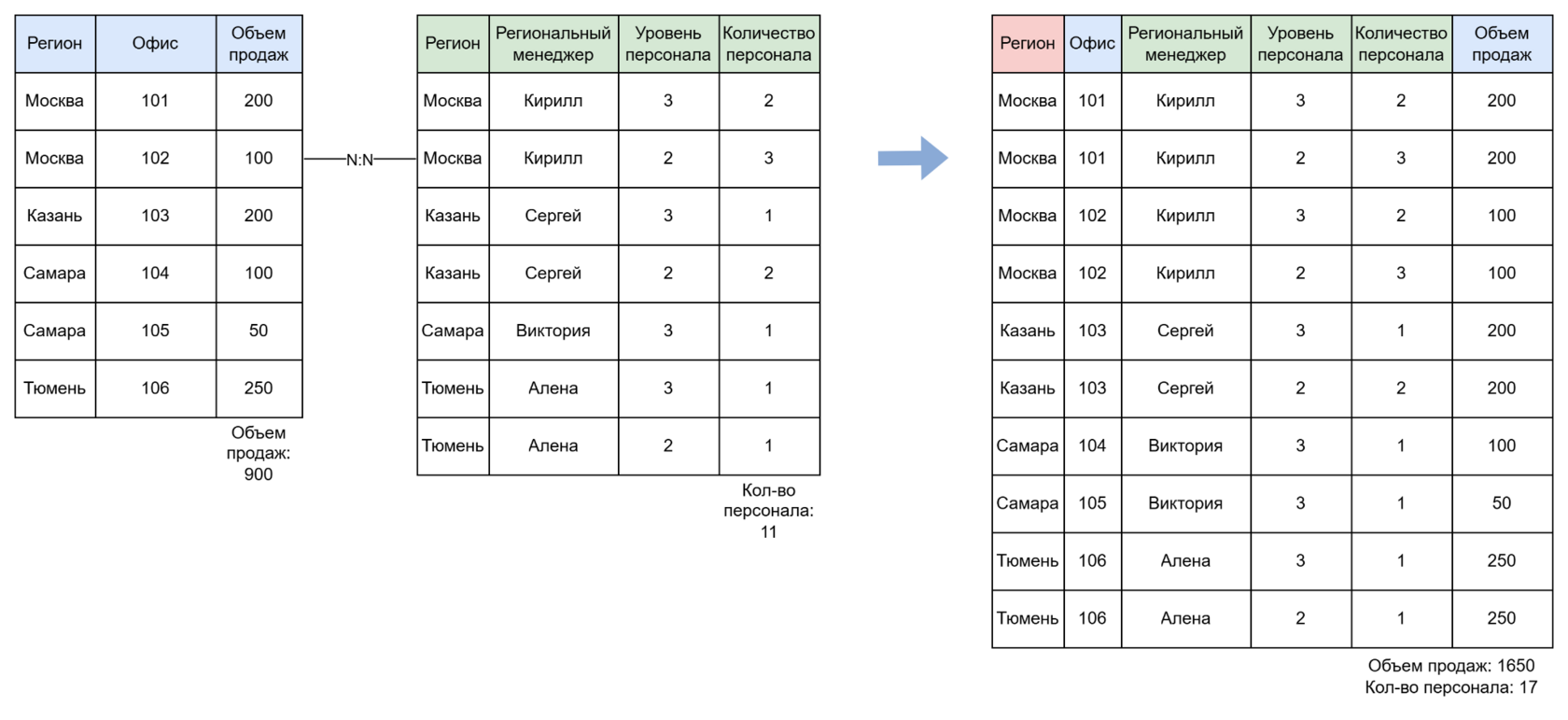
Вывод: объединения на уровне строк (как SQL JOIN) при дублированиях приводят к увеличению данных.
Логика объединения в модели рабочей книги#
Теперь о том, почему объединение в модели рабочей книги не приводит к увеличению данных и дублированию.
Главные принципы: 1. В объединении участвуют только использованные в анализе и связывающие (ассоциативные) поля. 2. Сначала выполняется агрегирование, а уже потом слияние.
Объединение в модели делится на три шага: 1. Система определяет, какие поля перенесены в область анализа компонента — только они (и ассоциативные) попадают в объединение. 2. Данные в таблицах агрегируются по связывающим полям и полям, использованным в области анализа. 3. Полученные агрегированные таблицы объединяются.
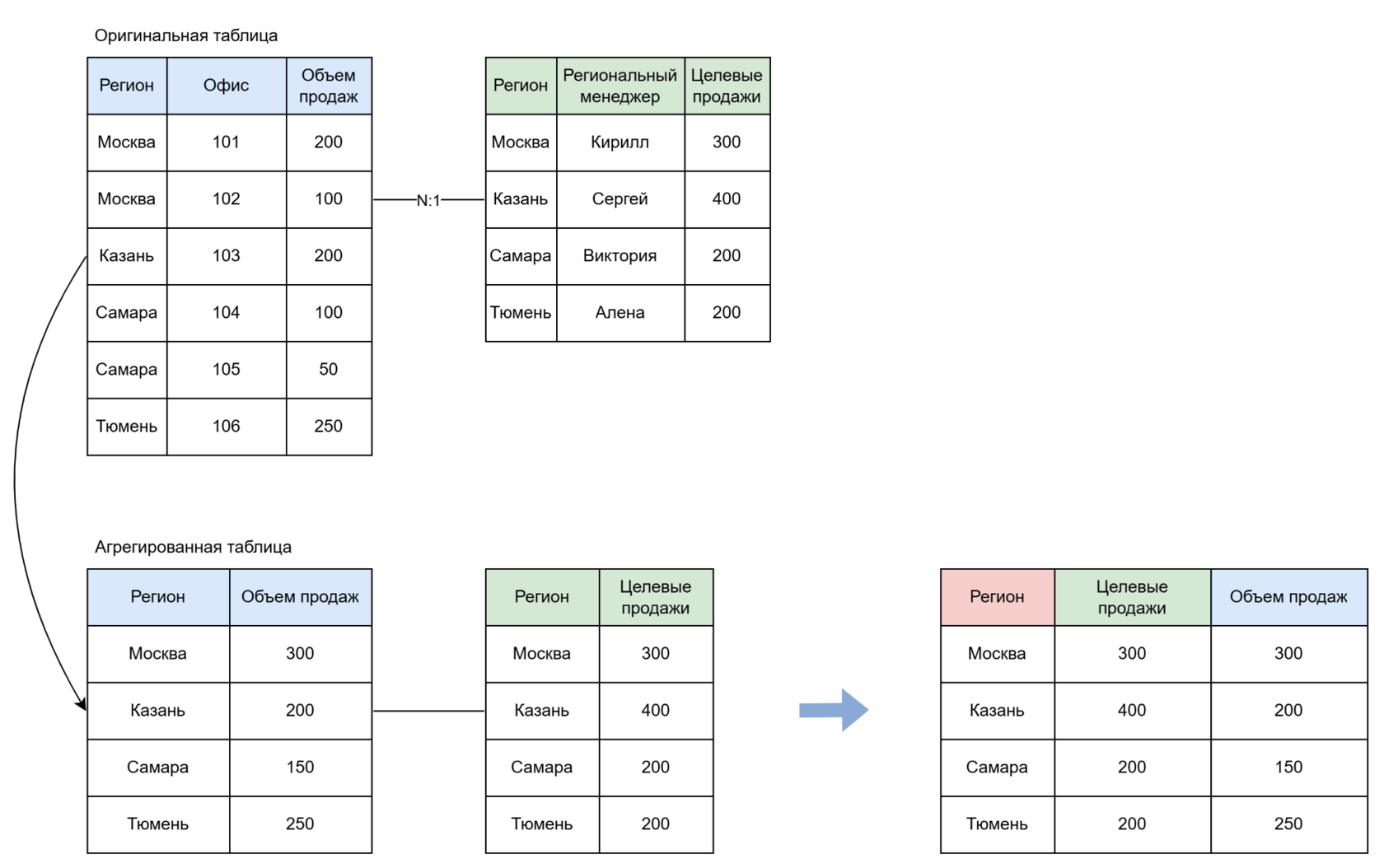
Например, если вы анализируете выполнение плана по регионам, используются поля Регион, Объём продаж и Целевые продажи:
В объединении участвуют только эти три поля.
Данные агрегируются по региону и этим полям.
На выходе — итоговая таблица по региону без дублирования и увеличения.
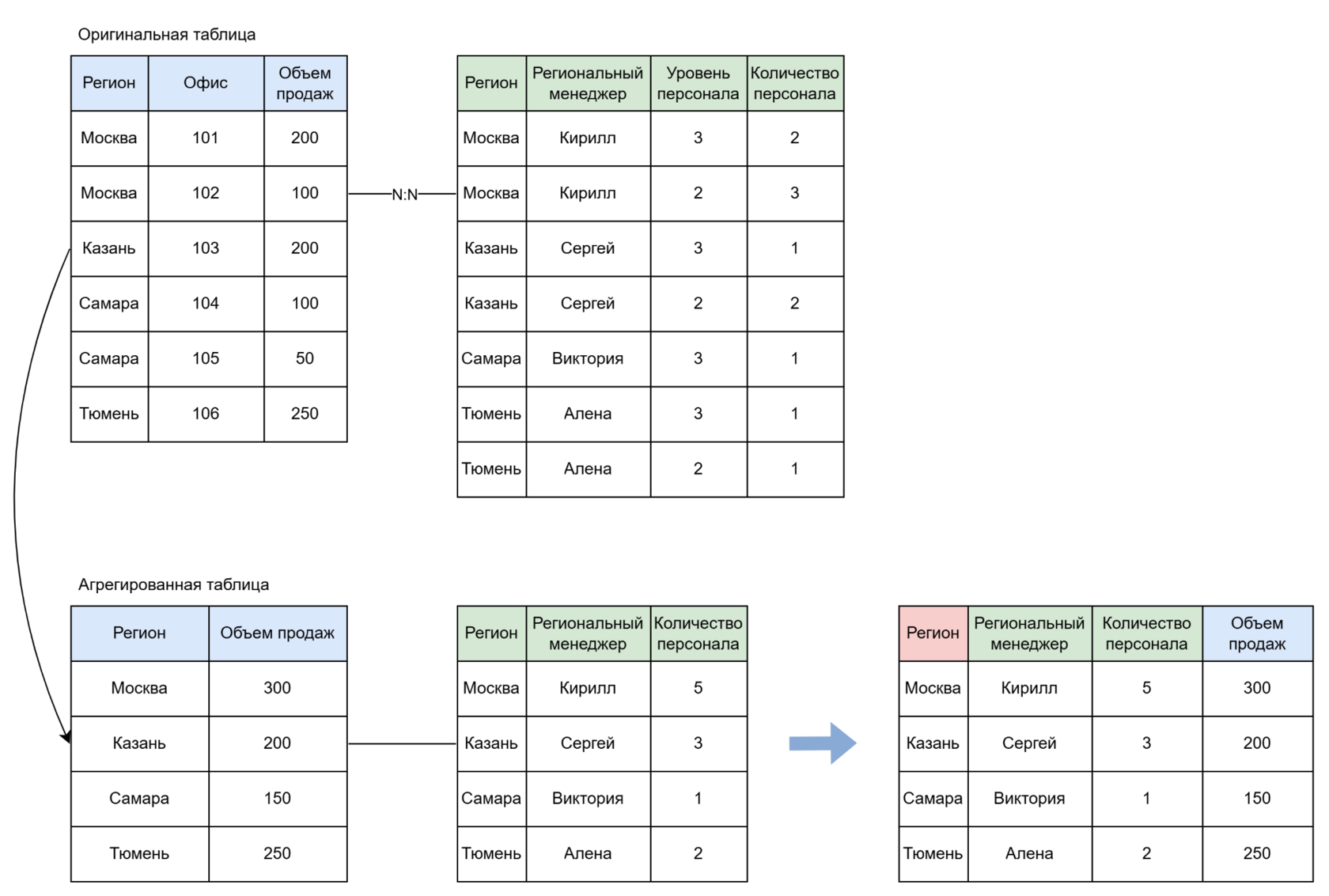
Пример для сценария N-к-N:
Если нужно посмотреть средний объём продаж на сотрудника по командам региональных менеджеров (Региональный менеджер, Объём продаж, Число сотрудников):
В объединении участвуют именно эти три поля и ещё ассоциативное поле Регион.
Данные агрегируются по менеджеру и перетаскиваемым полям.
Итоговые таблицы соединяются по полю Регион.
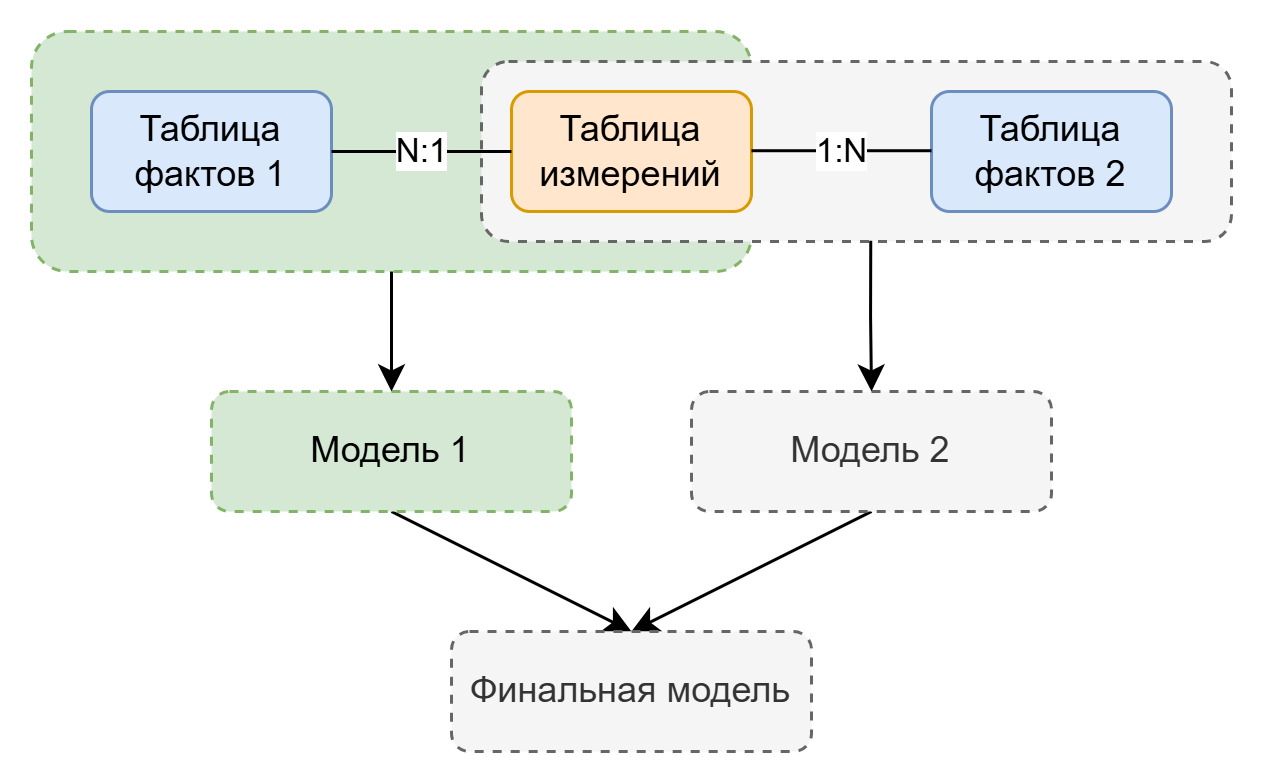
Работа с несколькими таблицами#
Если модель включает больше двух таблиц, система объединяет их попарно по правилам выше, формируя итоговую таблицу для анализа.
Например, если нужно анализировать поля из Таблицы фактов 1 и Таблицы фактов 2 — система последовательно объединяет каждую из них с Таблицей измерений, а затем соединяет их друг с другом для итогового анализа.
Гарантия целостности данных в модели#
Для соединения (джойн) можно руками выбрать, какие части данных сохранить (Левое соединение/Правое соединение/Объединение/Пересечение).
В модели рабочей книги таких опций нет, но система всё равно гарантирует целостность данных. Подробнее см. «Обеспечение целостности данных в модели рабочей книги».